
今回はGoogle Earth Engine(GEE)上で機械学習モデルで学習と予測を行う方法を紹介します
GEE上では決定木、ランダムフォレスト、ブースティング木、K-近傍法、SVM、ナイーブベイズ分類器などが使えます
基本的に機械学習モデルの引数は異なりますが、それに至るまでの手順は一緒になります
今回はランダムフォレストを使っていきますが、ランダムフォレストの定義部分を変えてもらえれば同じことができると思うのでぜひ試してみてください
ソースコードだけを見たい方はこちらから
手順
大まかな手順は正解データの用意、データの整形、モデルの定義、モデルの学習、精度検証になります
正解データの用意
まずは、データの用意をします
今回はGoogle Earth Engine Dataset上にあるMODISからNDVIを算出してくれているデータセットを使います
コードだとこのようになります
var dataset = ee.ImageCollection('LANDSAT/LC08/C01/T1_32DAY_NDVI').filterDate('2018-01-01', '2018-12-31');
var ndvi = dataset.select('NDVI').median();
Map.setCenter(131.4325, 31.8442, 10);
Map.addLayer(ndvi);次に正解データを用意します
こちらはee.Geometryで容易する必要があります
また、GEE上のポリゴン作成ツール上からでもインポートできます
インポートする場合はこのように、分類したいクラスごとにポリゴンを分けて作成してください
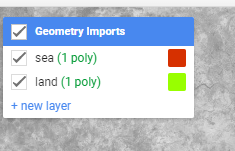
ポリゴンを作成するのが面倒くさい方はこちらをそのままコピペしてみてください!
var sea = ee.Geometry({
"type": "Polygon",
"coordinates": [
[[131.49705254467017,31.931674468692545],
[131.47507988842017,31.847721354715404],
[131.5039189997483,31.790542852705553],
[131.4874395075608,31.71580743663545],
[131.60142266185767,31.71580743663545],
[131.60142266185767,31.81388529310435],
[131.5808232966233,31.907196050862545],
[131.49705254467017,31.931674468692545]]
]
});
var land = ee.Geometry({
"type": "Polygon",
"coordinates": [
[[131.16608940990454,31.949155063780058],
[131.03425347240454,31.827887926453258],
[131.18668877513892,31.672573515050868],
[131.3336309138108,31.74384028743355],
[131.38993584545142,31.816219212793197],
[131.33500420482642,31.916521930540263],
[131.24436699779517,31.971292377027723],
[131.16608940990454,31.949155063780058]]
]
});データの整形
GEEで機械学習モデルを動作させるときは、FeatureCollectionにする必要があります。
そこで、まずポリゴンを下記のようにFeatureCollectionにします
var polygons = ee.FeatureCollection([
ee.Feature(sea, {"class": 0}),
ee.Feature(land, {"class": 1}),
]);Classには分類したいクラスラベルを指定します
今回は海と陸の二クラス分類にしています
次に、画像からポリゴンの範囲のデータをFeatureCollectionで取得します。
var training = ndvi.sampleRegions({
collection: polygons,
properties: ['class'],
scale: 100
});sampleRegions関数は画像に対して指定のポリゴンを取り出す関数です。
Scale引数で100を指定してますが、これが取り出す際の解像度になります。
小さくすると多くのデータを取り出せますが、メモリエラーになることもあるので注意です
機械学習モデルを使うときは基本的にデータをシャッフルし、学習データとテストデータに分割します
GEEでこれをやる場合にはrandomColumn関数を使い、取り出したデータに対して0から1までの値を加えた後、Fillter関数で学習データとテストデータを取り出します
コードで書くとこんな感じになります
var sample = training.randomColumn();
// 訓練データの作成
var train_data = sample.filter(ee.Filter.lt('random', 0.8));
// テストデータの作成
var test_data = sample.filter(ee.Filter.gte('random', 0.8));randomColumn関数の返り値に対してFilter関数で80%と20%のデータ数で分割しています
機械学習モデルの定義
次に機械学習モデルの定義と学習を行っていきます
まずGEEで使える機械学習モデルは決定木、ランダムフォレスト、ブースティング木、K-近傍法、SVM、ナイーブベイズ分類器などが使えます
今回はランダムフォレストを使っていきます
ランダムフォレストはee.Classifier.smileRandomForestで定義できます
学習する際は定義後のモデルに対してtrain関数を使います
train関数を使う際は学習データの正解ラベルのプロパティ(今回はclass)や学習に使うバンドの名前を設定します
今回は学習データとしてtrain_data変数をfeatures引数に指定しています
// ランダムフォレストを定義
var classifier = ee.Classifier.smileRandomForest(10);
var bands = ndvi.bandNames();
// ランダムフォレストの学習
var trained_rdf = classifier.train({
features: train_data,
classProperty: 'class',
inputProperties: bands
});学習をした後に予測を行います
予測をする際はFeatureCollectionで使えるclassify関数を使います
classify関数の引数に学修済みモデルを与えてあげれば、データの予測ができます
// テストデータの予測
var test_result = test_data.classify(trained_rdf);精度検証
最後に精度検証をします
精度検証をする際はKappa係数、正解率などが使えます
これらの精度指標は混合行列にしないと使えないので、まずはテストデータの混合行列を用意します
混合行列はclassify関数の帰り値に対して、errorMatrix関数を使うと取得できます
// テストデータの混合行列を取得
var test_confusion_matrix = test_result.errorMatrix('class', 'classification');各評価指標は下記のように取得した混合行列に対してaccuracy関数、kappa関数を使うとGEE上で計算してくれます
// 混合行列を表示
print(test_confusion_matrix);
// 正解率
print(test_confusion_matrix.accuracy());
// Kappa係数
print(test_confusion_matrix.kappa());これでテストデータに対する精度が分かりますね
今回は正解率だと99%ぐらいになると思います
ソースコード
最後に今回のソースコードの全体を紹介します。
ポリゴンもソースコード上に記載しているので、コピペで動くと思います!
GEE上ですぐに動かしたい方はこちらからも動作できるので、確認してみてください!
var dataset = ee.ImageCollection('LANDSAT/LC08/C01/T1_32DAY_NDVI').filterDate('2018-01-01', '2018-12-31');
var ndvi = dataset.select('NDVI').median();
Map.setCenter(131.4325, 31.8442, 10);
Map.addLayer(ndvi);
// 正解データの用意
var sea = ee.Geometry({
"type": "Polygon",
"coordinates": [
[[131.49705254467017,31.931674468692545],
[131.47507988842017,31.847721354715404],
[131.5039189997483,31.790542852705553],
[131.4874395075608,31.71580743663545],
[131.60142266185767,31.71580743663545],
[131.60142266185767,31.81388529310435],
[131.5808232966233,31.907196050862545],
[131.49705254467017,31.931674468692545]]
]
});
var land = ee.Geometry({
"type": "Polygon",
"coordinates": [
[[131.16608940990454,31.949155063780058],
[131.03425347240454,31.827887926453258],
[131.18668877513892,31.672573515050868],
[131.3336309138108,31.74384028743355],
[131.38993584545142,31.816219212793197],
[131.33500420482642,31.916521930540263],
[131.24436699779517,31.971292377027723],
[131.16608940990454,31.949155063780058]]
]
});
// クラスラベルの定義
var polygons = ee.FeatureCollection([
ee.Feature(sea, {"class": 0}),
ee.Feature(land, {"class": 1}),
]);
// データの取り出し
var training = ndvi.sampleRegions({
collection: polygons,
properties: ['class'],
scale: 100
});
// データのシャッフルと値付け
var sample = training.randomColumn();
// 訓練データの作成
var train_data = sample.filter(ee.Filter.lt('random', 0.8));
// テストデータの作成
var test_data = sample.filter(ee.Filter.gte('random', 0.8));
// ランダムフォレストを定義
var classifier = ee.Classifier.smileRandomForest(10);
var bands = ndvi.bandNames();
// ランダムフォレストの学習
var trained_rdf = classifier.train({
features: train_data,
classProperty: 'class',
inputProperties: bands
});
// テストデータの予測
var test_result = test_data.classify(trained_rdf);
// テストデータの混合行列を取得
var test_confusion_matrix = test_result.errorMatrix('class', 'classification');
// 混合行列を表示
print(test_confusion_matrix);
// 正解率
print(test_confusion_matrix.accuracy());
// Kappa係数
print(test_confusion_matrix.kappa());
// F1スコア
print(test_confusion_matrix.fscore());
コメント